

AI adoption is accelerating across industries. Organizations are integrating Large Language Models (LLMs) into customer support platforms, internal copilots, document processing systems, software development workflows, and agentic AI applications. While this unlocks tremendous business value, it also introduces a new operational challenge: unpredictable AI costs.
Unlike traditional APIs, AI workloads are not charged based on the number of requests. They are charged based on the number of tokens consumed. A simple prompt might consume only a few tokens, while a complex AI-generated report can consume thousands. Yet most traditional rate limiting systems treat both requests exactly the same.
This creates a governance gap. Teams can easily exceed budgets, shared AI resources can become monopolized by a few users, and finance teams often struggle to predict monthly AI spending.
So, how do organizations enforce meaningful AI consumption policies?
This is where Usage-Based Rate Limiting in Envoy AI Gateway becomes essential.
In this blog, we’ll explore how Usage-Based Rate Limiting works, the architecture behind it, how token-aware enforcement is implemented using Redis, and how organizations can use it to build cost-efficient and production-ready AI platforms.
Video on Envoy AI Gateway Usage-Based Rate Limiting
In case you want the video, here it is
Why Traditional Rate Limiting Breaks Down for AI Workloads
Before understanding Usage-Based Rate Limiting, it’s important to understand why conventional approaches struggle in AI environments.
Traditional API gateways typically enforce limits based on:
- Requests per second
- Requests per minute
- Requests per user
These controls work well for REST APIs because requests generally have comparable resource consumption.
AI systems are fundamentally different.
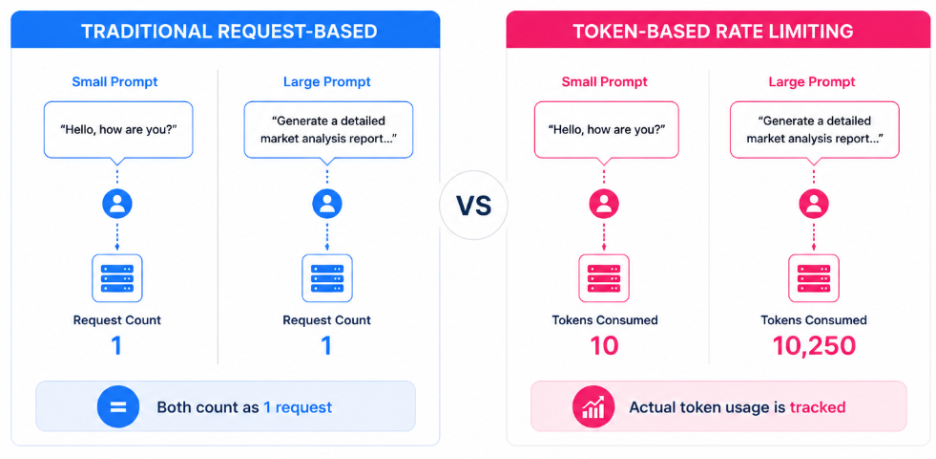
Consider the following example:

From a traditional gateway perspective, both count as a single request.
From a cost perspective, they are vastly different.
As AI adoption grows, organizations begin encountering challenges such as:
Unpredictable AI spending
Shared resource exhaustion
Uncontrolled model consumption
Lack of tenant-level governance
Difficulty enforcing departmental budgets
To solve these problems, organizations need a way to control what actually drives AI costs: tokens.
This leads us directly to Usage-Based Rate Limiting.
From a traditional gateway’s perspective, both count as a single request.
From a cost perspective, they are vastly different.
As AI adoption grows, organizations begin encountering challenges such as:
- Unpredictable AI spending
- Shared resource exhaustion
- Uncontrolled model consumption
- Lack of tenant-level governance
- Difficulty enforcing departmental budgets
To solve these problems, organizations need a way to control what actually drives AI costs: tokens.
This leads us directly to Usage-Based Rate Limiting.
What is Usage-Based Rate Limiting?
Usage-Based Rate Limiting is a token-aware traffic management mechanism designed specifically for AI workloads.
Instead of measuring the number of requests, Envoy AI Gateway measures the amount of AI consumption associated with each request.
The gateway continuously tracks:
- Input tokens
- Output tokens
- Total token usage
- Per-user consumption
- Per-model consumption
- Remaining budget availability
When a user exceeds their allocated budget, the gateway immediately blocks additional requests.
This creates a proactive governance model where spending limits are enforced automatically rather than discovered after invoices arrive.
A few key advantages include:
- Real-time budget enforcement
- Cost-aware traffic management
- Per-user isolation
- Multi-tenant governance
- No application code change
Now that we’ve established what Usage-Based Rate Limiting is, let’s examine the components that make it possible.
Architecture Overview
At a high level, Envoy AI Gateway combines traditional gateway capabilities with AI-specific intelligence and token accounting.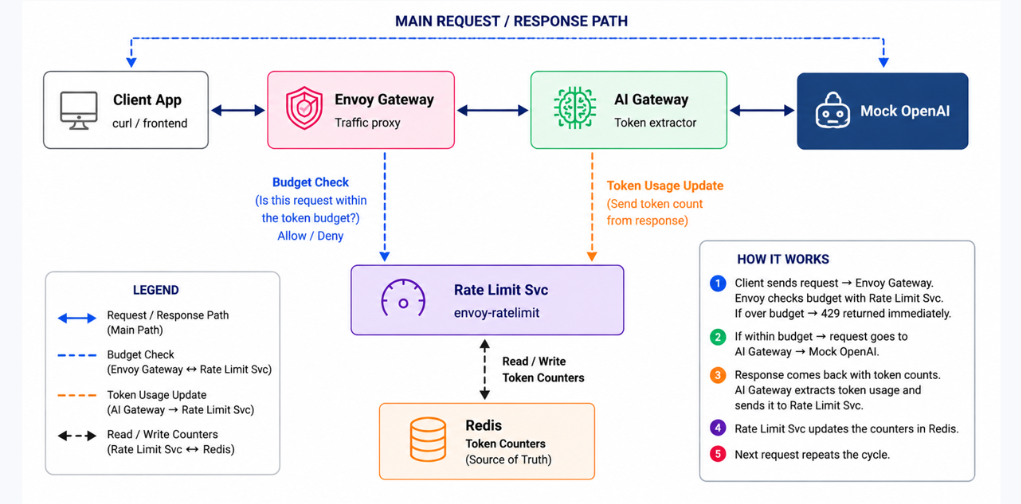 The architecture consists of five major components.
The architecture consists of five major components.
Client Applications
Applications send requests to the gateway along with tenant identifiers.
Envoy Gateway
Acts as the primary traffic entry point and policy enforcement layer.
Envoy AI Gateway
Provides AI-native capabilities including:
- Token extraction
- Usage accounting
- Budget management
- AI governance policies
Redis
Redis serves as the real-time storage layer for:
- User budgets
- Model budgets
- Token counters
- Consumption history
LLM Providers
Requests are ultimately forwarded to providers such as:
- OpenAI
- Anthropic
- Gemini
- Azure OpenAI
The combination of Envoy AI Gateway and Redis enables near real-time budget enforcement across all AI traffic.
Understanding the Request Lifecycle
The architecture becomes much clearer when we follow a request through the system.
Let’s walk through the entire lifecycle.
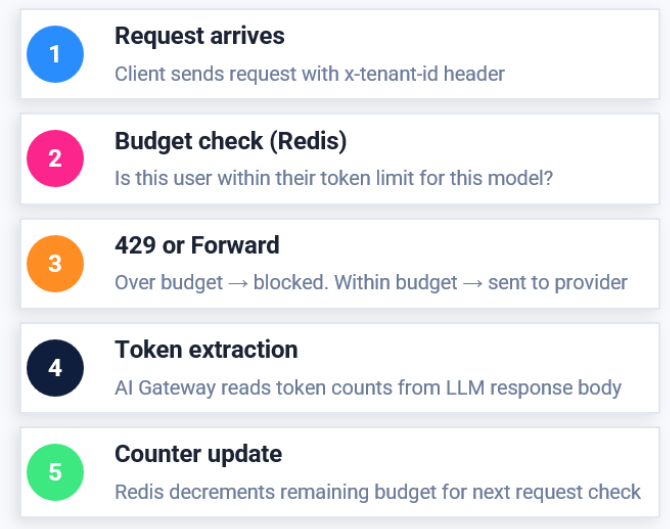
Step 1: Request Arrives
A client sends a request to the AI Gateway along with a tenant identifier, such as x-tenant-id: alice. This identifier allows the gateway to determine which budget and rate-limiting policies should be applied.
Step 2: Budget Check (Redis)
Before forwarding the request to an LLM provider, Envoy AI Gateway checks Redis to determine whether the user still has available tokens within their assigned budget for the selected model.
Step 3: Allow or Block
If sufficient budget remains, the request is forwarded to the LLM provider for processing. If the user has exceeded their token allocation, the gateway immediately returns a 429 Too Many Requests response, preventing additional AI costs.
Step 4: Token Extraction
After the model generates a response, Envoy AI Gateway reads the token usage information returned by the provider. Depending on the configuration, this may include input tokens, output tokens, cached tokens, or total tokens consumed.
Step 5: Counter Update
The consumed token count is written back to Redis, updating the user’s remaining budget. This updated value becomes the reference point for the next request, enabling continuous real-time budget enforcement.
As a result, every request continuously contributes to an accurate usage record, allowing organizations to control AI spending, enforce tenant isolation, and prevent budget overruns without modifying application code.
Now that we’ve seen how usage is tracked, the next question becomes: what exactly can we measure?
Token Types and Usage Calculations
Not all tokens contribute equally to AI workloads.
Envoy AI Gateway allows organizations to track multiple token categories.
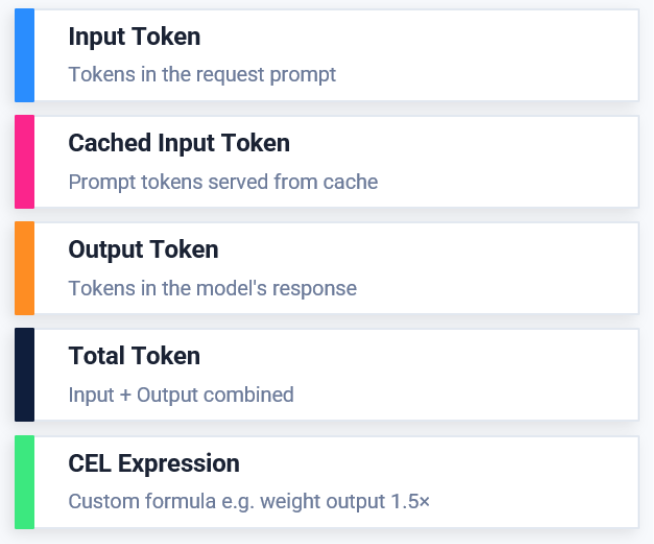
Input Tokens
Tokens contained within the user prompt.
Useful for controlling prompt-heavy workloads.
Cached Input Tokens
Tokens served from cache rather than newly processed by the model.
Particularly valuable for RAG and prompt caching architectures.
Output Tokens
Tokens generated by the model.
Often the largest contributor to inference costs.
Total Tokens
A combined measurement of:
Input Tokens + Output Tokens
This is the most common budgeting model.
CEL Expressions
Organizations frequently need more advanced accounting models.
This is where CEL expressions become valuable.
Example:
Input Tokens + (Output Tokens × 1.5)
This allows teams to weigh expensive operations differently and align Rate Limiting with the actual business costs.
Understanding these token types opens the door to more sophisticated governance strategies.
Now let’s understand a sample demonstration of the solution
Budget Enforcer Demo Walkthrough
To demonstrate token-aware enforcement, a sample environment was deployed using:
- AKS
- Envoy Gateway v1.3.1
- Envoy AI Gateway v0.1.5
- Redis
- Mock OpenAI Server
This setup simulated real-world AI traffic without requiring production API credentials.
Scenario
A user named Alice is assigned a token budget.
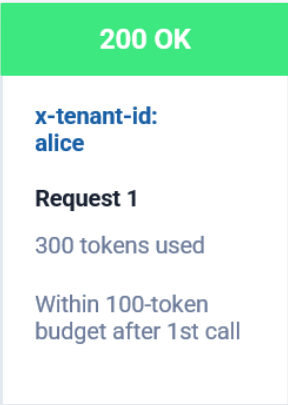
Request 1
200 OK
300 tokens are consumed.
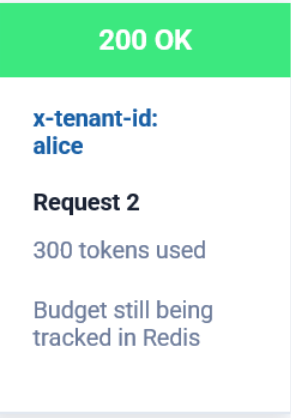
Request 2
200 OK
Another 300 tokens are consumed.
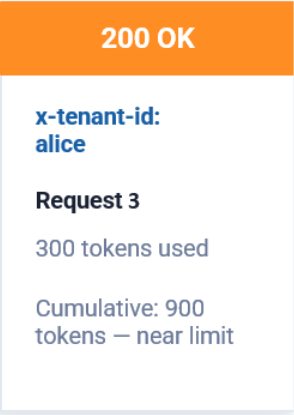
Request 3
200 OK
Total consumption reaches 900 tokens.
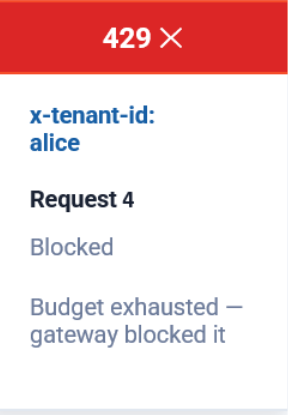
Request 4
429 Too Many Requests
Budget exhausted.
Request blocked.
A second user, Bob, sends requests during the same period.
Bob continues receiving successful responses because his budget is managed independently.
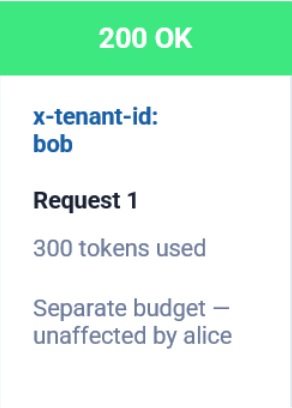
This demonstrates two important principles:
- Token-aware enforcement
- Tenant isolation
Most importantly, all enforcement occurred at the gateway layer with zero application changes required.
Key Benefits for Enterprise AI Platforms
The key benefits are:
- Predictable AI Spending
- Fair Resource Distribution
- Multi-Tenant Governance
- Better Visibility
- Enterprise-Scale Operations
Ultimately, Usage-Based Rate Limiting transforms AI cost management from a reactive process into a proactive control mechanism.
Final Thoughts
As AI adoption scales, Usage-Based Rate Limiting becomes a critical capability for controlling costs, enforcing fair usage, and governing AI consumption across teams and applications. Envoy AI Gateway provides the foundation for implementing these controls at scale, helping organizations build secure, cost-efficient, and production-ready AI platforms.
If you’re planning to deploy Envoy AI Gateway in production and need expert guidance, architecture reviews, implementation support, troubleshooting assistance, or ongoing enterprise support, contact IMESH





