

What is Kubernetes RBAC
Often when organizations start their Kubernetes journey, they look upto implementing least privilege roles and proper authorization to secure their infrastructure. That’s where Kubernetes RBAC is implemented to secure Kubernetes resources such as sensitive data, including deployment details, persistent storage settings, and secrets.
Kubernetes RBAC provides the ability to control who can access each API resource, with what kind of access. You can use RBAC for both human (individual or groups) and non-human users (service accounts) to define their types of access to various Kubernetes resources.
For example there are the 3 different environments called Dev, Staging and Production, which have to be given access to the team such as developers, DevOps, SREs, App owner, product managers.
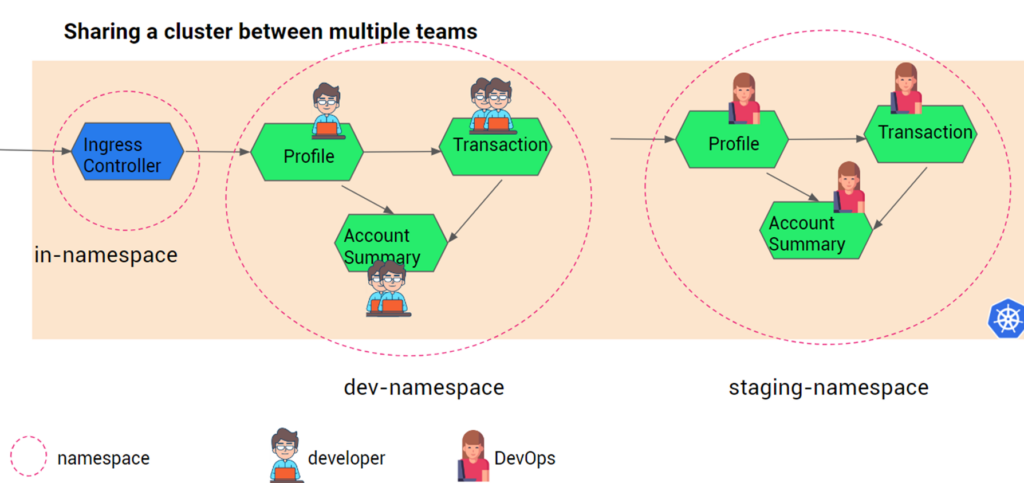
Before we get started we would like to stress that we will treat users and service accounts as the same, from a level of abstraction- every request either from a user or a service account is finally an HTTP request. Yes we understand users and service accounts (for non-human users) are different in nature in Kubernetes.
How to enable Kubernetes RBAC
One can enable RBAC in Kubernetes by starting the API server with authorization-mode flag on. Kubernetes resources used to apply RBAC on users are:
- Role,
- ClusterRole,
- RoleBinding,
- ClusterRoleBinding
Service Account
To manage users Kubernetes provides an authentication mechanism, but it is usually advisable to integrate Kubernetes with your enterprise identity management for users such as Active Directory or LDAP. When it comes to non-human users (or machines or services) in a Kubernetes cluster then the concept of Service Account comes into picture.
For e.g. The Kubernetes resources need to be accessed by a CD application such as Spinnaker or Argo to deploy applications, or one pod of a service A needs to talk to another pod of service B. In such cases Service Account is used to create an account of a non-human user, and specify required authorization ( using RolesBinding or ClusterRoleBinding).
You can create Service Account by creating a yaml like below:
apiVersion: v1
kind: ServiceAccount
metadata:
name: nginx-saspec: automountServiceAccountToken: falseAnd then apply it.
$ kubectl apply -f nginx-sa.yaml
serviceaccount/nginx-sa createdAnd now you have to ServiceAccount for pods in the Deployments resource.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx1
labels:
app: nginx1
spec:
replicas: 2
selector:
matchLabels:
app: nginx1
template:
metadata:
labels:
app: nginx1
spec:
serviceAccountName: nginx-sa
containers:
- name: nginx1
image: nginx
ports:
- containerPort: 80In case you don’t specify about serviceAccountName in the Deployment resources then the pods will belong to ‘default’ Service Account. Note, there is the default Service Account for each namespace and one for clusters. And all the default authorization policies as per the default Service Account will be applied to the pods where Service Account info is not mentioned.
In the next section, we will see how to assign various permissions to a Service Account using RoleBinding and ClusterRoleBinding.
Role and ClusterRole
Roles and ClusterRoles are the Kubernetes resources used to define the list of actions a user can perform within a namespace or a cluster respectively.
In Kubernetes the actors such as users, group or ServiceAccount are called subjects. The actions that a subject can take such as create, read, write, update, and delete are called verbs.
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: read-only
namespace: dev-namespace
rules:
- apiGroups:
- ""
resources: ["*"]
verbs:
- get
- list
- watchIn the above Role resource, we have specified that the ‘read-only’ role is only applicable to deb-ns namespace and to all the resources inside the namespace. Any ServiceAccount or users which would be bound to ‘read-only’ role can take these actions- get, list and watch.
Similarly the ClusterRole resource will allow you to create roles pertinent to clusters. Example given below:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: chief-role
rules:
- apiGroups:
- ""
resources: ["*"]
verbs:
- get
- list
- watch
- create
- update
- patch
- deleteAny user/group/ServiceAccount bound to chief-role will be able to take any action in the cluster.
In the next section we will see how to grant roles to subjects using RoleBinding and ClusterRoleBinding.
Also note, Kubernetes allows you to configure custom roles using Role resource or use default user-facing roles such as the following:
- Cluster-admin: For cluster administrators, Kubernetes provides a “superuser” Role. The Cluster admin can perform any action on any resource in a cluster. One can use ‘superuser’ in a ClusterRoleBinding to grant full control over every resource in the cluster (and in all namespaces) or in a RoleBinding to grant full control over every resource in the respective namespace.
- Admin: Kubernetes provide ‘admin’ Role to permit unlimited read/write access to resources within a namespace. ‘admin’ role can create roles and role bindings within a particular namespace. It does not permit write access to the namespace itself. This can be used in the RoleBinding resource.
- Edit: ‘edit’ role grants read/write access within a given Kubernetes namespace. It cannot view or modify roles or role bindings.
- View: ‘view’ role allows read-only access within a given namespace. It does not allow viewing or modifying of roles or role bindings.
RoleBinding and ClusterRoleBinding
To apply the Role to a subject (user/group/ServiceAccount), you must define a RoleBinding. This will give the user least privilege access to required resources within the namespace with the permissions defined in the Role configuration.
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: RoleBinding
metadata:
name: Role-binding-dev
roleRef:
kind: Role
name: read-only #The role name you defined in the Role configuration
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: User
name: Roy #The name of the user to give the role to
apiGroup: rbac.authorization.k8s.io
- kind: ServiceAccount
name: nginx-sa#The name of the ServiceAccount to give the role to
apiGroup: rbac.authorization.k8s.ioSimilarly, ClusterRoleBinding resources can be created to define the Roles to users. Note we have used the default ‘superuser’ ClusterRole reference provided by Kuebrnetes instead of using our custom role. This can be applied to cluster administrators.
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: superuser-binding
roleRef:
kind: ClusterRole
name: superuser
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: User
name: Aditi
apiGroup: rbac.authorization.k8s.ioBenefits of Kubernetes RBAC
The advantage of Kubernetes RBAC is it allows you to “natively” implement least privileges to various users and machines in your cluster. The key benefits are:
Proper Authorization
With least privileges to various users and Service Accounts to Kubernetes resources, DevOps and architects can implement one of the main pillars of zero trust. Organizations can reduce the risk of data breaches and data leakage, and also avoid internal employees accidentally deleting or manipulating any critical resources.
Separation of Duties
Applying RBAC on Kubernetes resources will always facilitate separation of duties of users such as developers, DevOps, testers, SREs, etc in an organization. For e.g. for creating/deleting a new resource in dev environment, developers should not depend on admin. Similarly deploying new applications into test servers and deleting the pods after testing should not be a bottleneck for DevOps or testers. Applying authorization and permissions to users such as developers and CI/CD deployment agents into respective workspaces (say namespaces or clusters) will decrease the dependencies and cut the slack.
100% adherence to compliance
Many industry regulations such as HIPAA, GDPR, SOX, etc, demand tight authentication and authorization mechanisms in the software field. Using Kubernetes RBAC, DevOps and architects can quickly implement RBAC into their Kubernetes cluster and improve their posture to adhere to those standards.
Disadvantages of Kubernetes RBAC
For small and medium enterprises using Kubernetes RBAC is justified, but it is not advisable to use Kubernetes RBAC for the below reasons:
- There can be many users and machines and applying Kubernetes RBAC can be cumbersome to implement and maintain.
- Granular visibility of who performed what operation is difficult. For e.g. large enterprises would require information such as violations or malicious attempts against RBAC permissions.
RBAC implementation in Kubernetes using Istio service mesh
Istio is an open-source service mesh software that helps DevOps, architects, and SREs simplify the traffic management, security, and observability of microservices in the cloud.
Istio can also help DevOps and architects implement RBAC and multi-tenancy. However, there can be easy-to-complicated scenarios:
- Single cluster-multiple namespace
- Multicluster-multiple namespaces
- Multicloud-multiple cluster (multiple namespaces)
I have covered a blog explaining the above 3 scenarios and how to implement RBAC in each of them using Istio, in detail. Check it out here: Implementing stronger RBAC and Multitenancy in Kubernetes using Istio.





