

What is eBPF?
The operating system implements security, networking, and observability because of the kernel’s capability to visualize and control the entire technology stack. However, it isn’t easy to improve a kernel because it is built specifically for OS stability and security. Hence, innovation has always happened in the user space, i.e., functionality outside the OS rather than in the OS kernel. But thanks to eBPF technology, which has laid the path for ground-breaking innovations in networking, security, and observability at the kernel level.
eBPF is a new technology that extends the Linux OS kernel without requiring a change in the source kernel code. This means that eBPF can allow programs to enhance the operating system’s capabilities and run much faster and more efficiently than in the user space. The speed and efficiency gain happen because of the OS’s robust and fast compiler and verification engine.
Simply put, you can think of the scenario of the early 2000s when static web pages were written on the top browsers (web applications). The browser type and versions were important for developers while developing web pages. But with the introduction of Javascript, the programmability increased and the developers could innovate faster without depending on the browsers that a user might run on his laptop. Today, a webpage can be a full-blown SaaS application.
There are many use cases of eBPF, such as:
- Providing high-performance networking for cloud-native apps
- Faster L3/L4 authorization of traffic
- Extraction of fine-grained observability (metrics, logs, and traces) at low overhead
- Insights for troubleshooting application performance
- Preventive policy for application and container runtime security enforcement
- and more.

Image source: https://ebpf.io/
The innovation has started, and many eBPF-based projects are emerging (refer to the above image) in next-generation networking, observability, security functionality, etc.
Architecture of eBPF
Let us first understand the OS architecture before turning to eBPF. The OS kernel provides system calls (or API calls) for the applications to interact with the hardware, such as storage and the network. The abstraction of underlying hardware and virtual hardware from the application layer allows the efficient usage of the hardware resources. The OS kernel ( refer to the below image of Linux Kernel) offers a comprehensive subsystem to distribute the task of applications using various efficient algorithms. The subsystem allows limited configuration to cater to multiple requirements in the enterprise (of course, this is possible only with open-source Linux).

In the Linux world, the kernel can change either with the community’s help or by writing a new kernel module yourself. There are risks in both approaches- you might have to wait for several years before the community comes up with a configuration suited to your requirements; on the contrary, you will always need more expertise to develop a bug-free and performant kernel module in-house. Kernel programming is not easy, and a few endangered species in the world understand kernel programming. This is why the innovation in the Linux kernel has always been a challenge.
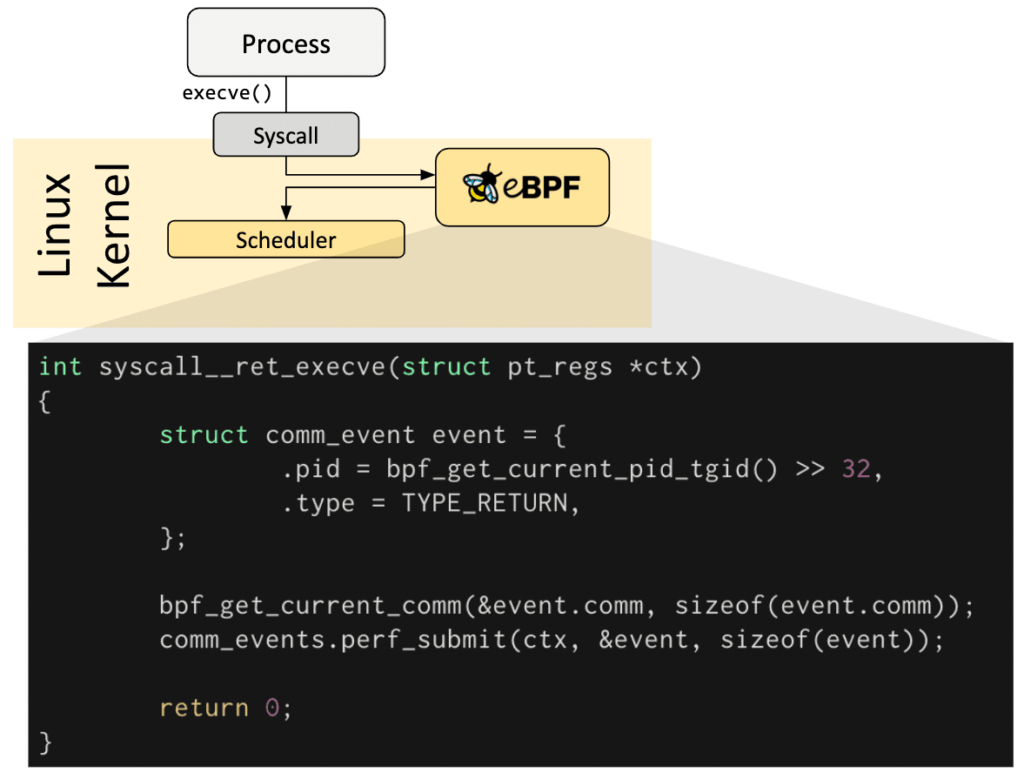
But thanks to eBPF, there is a way to program the subsystems in the Linux kernel without requiring to change the kernel source code. The user space thread can interact with eBPF and it can interact with the sub system process (refer the image below). eBPF provides the functionality to run sandbox programs in the kernel which can be triggered (referred to as hooks) when there is an event such as system calls, function entry/exit, kernel tracepoints, network events, etc. In the image below, whenever the execve syscalls happen, the eBPF program is triggered, and current process time is calculated using functions.
If you don’t have any predefined hook (or trigger points) then it is possible to create a kernel probe (kprobe) or user probe (uprobe) to attach eBPF programs almost anywhere in kernel or user applications. eBPF is very good for solving gaps in the observability such as trace profiling.
Various framework that allows you to get started with eBPF programming are:
- BCC- to write Python programs, especially to collect metrics and other stats from a running application.
- bpftrace– a high-level tracing language for Linux eBPF that uses LLVM compilers and BCC framework for interacting with the Linux eBPF subsystem.
- eBPF Go library– a library to decouple the process of generating eBPF bytecode, loading and other management of eBPF programs.
If interested, read about eBPF development tools.
Risk of using eBPF for kernel-level programming
All the above may sound like a risky adventure since eBPF deals with kernel subsystems. And yes, there are risks associated with the eBPF.
You see, the eBPF is not a machine code; they are bytecode for the VM in the kernel. The VM sandboxes them and enforces access controls so only privileged users can run eBPF programs. You can also perform static analysis of the eBPF program to ensure that the eBPF programs are not harmful and that no information leaks from the kernel to the user space.
Now that the intro to eBPF is over let us understand why it is becoming famous in the service mesh world.
Role of eBPF in Istio service mesh
We have read about the use cases of eBPF in network management and security controls at L3/L4 levels. So, eBPF can be used to carry out some tasks of sidecars or Envoy proxies.
The sidecar models are slower because of buffer-copying and context switching into the user space; simply, any packet from one service to another has to traverse through the TCP/IP and socket stack multiple times. And this part can be eliminated completely by using eBPF.
Please note: All the mesh features cannot be implemented into the kernel using eBPF. eBPF was developed to include specific requirements for seeds for faster processing but was not meant to build service mesh from the ground up. Creating HTTP filters (similar to Envoy) using eBPF is impractical and can be a nightmare; HTTP is a complex protocol with many new protocols: HTTP 1.1 or HTTP/2, gRPC, etc. We strongly urge you to discount any literature discussing replacing sidecars with eBPF. (Of course, you can use node-level proxy to improve the performance; it is the new and faster version of Istio called Ambient mesh.)
If you are an architect or DevOps engineer transforming the security and network landscape using Istio service mesh, consider eBPF for interception and redirection of traffic coming in and going out of service Envoy containers. Istio, by default, uses iptables rules to implement the ingress, egress, and forward traffic, but eBPF can be used for traffic to bypass the TCP/IP and the socket layer. You can observe improvement in the sidecar resource consumption.
Envoy sidecars’ latency and throughput improvement can vary on many things, such as the length and depth of microservices, Kubernetes CNI, network bandwidth, sidecar resource config, etc. As an Istio implementation partner to some of the large-scale systems, we have seen that the result can vary from 5% to 30%.
We will discuss the Istio performance optimization using eBPF in the next blog.
Conclusion
eBPF is surely a revolutionalised technology as it provides the capability to developers to inject bytecode that can run in kernel space (as sandboxed programs). Hence there are a lot of possibilities around the use cases such as observability, particularly tracing. However, the capability of eBPF should not be misinterpreted and used building anything from scratch like developing the sidecar functionalities in the kernel space. Careful evaluation of development and maintenance activities must be considered before using eBPF for any use case.





